
If you are a user of Scikit-learn, I think you heard about standarization and normalization already implemented in the library. Standarization and Normalization are used in different fields also, as terminology normalization can be seen in statistics, linear algebra, pattern recognition, etc and it means differently in each context. So it’s confusing at a glance, right? In machine learning and Scikit-learn especially, these are terminologies of data processing methods that are implemented in the library for feature scaling.
The purpose of feature scaling is to smooth data range in case the scale of features of the data set varies. For the classifiers that may use distances calculated from data points, it is essential to apply feature scaling technique to achieve effective use of the classifiers. When one of the features has a broad range of values, the distance will be governed by this particular feature. Using such techniques will merit consideration when you use distance-based classifiers such as K nearest neighbours, SVM, or Neural Network.
Another reason why we need feature scaling is that classifiers leveraging gradient decent converges much faster with feature scaling techniques. Here’s the good reference why we should use feature scaling in machine learning and when handling data set.
In this tutorial, I’ll explain how these standarization and normalization differ and test these techniques with iris data set in Scikit-learn. I wanted to confirm how applying these techniques impact the result. I used K nearest neighbors classifier to compare the results. Let’s load iris data set as below.
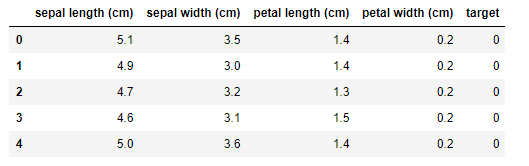
Standarization
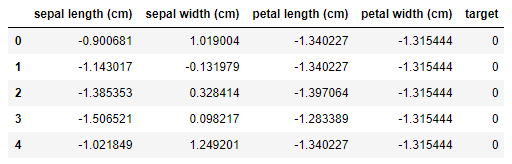
Standarization is described as Z-score normalization in Wikipedia feature scaling page. Yes right, you might already notice that this is one of statistics terminologies, making data values of each feature in data to have zero-mean (when subtracting the mean in the numerator) and unit-variance (the standard variation is one).
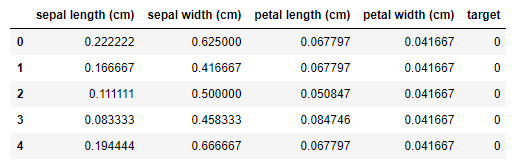
Normalization
Here’s a confusion. The terminology normalization implies the normal distribution, however normalization in this context is totally different concept. Normalization is described as Rescaling (min-max normalization) in Wikipedia feature scaling page. Normalization is the simplest method and consists in rescaling the range of features to scale the range in [0, 1] or [−1, 1]. In default, rescaling the range in [0, 1] is applied by the general fomula. Let’s take a look how we can code it.
Apply K nearest neighbors classifier
With this simple data set, the accuracies with 3 data set (the original one, the standarized one and the normalized one) were similar. I used mglearn library to draw decision boundaries between the classes of iris data set.
mglearn is the library of utility functions written for this book. You can install it easily with pip.
pip install mglearnI defined this simple function. The function takes DataFrame and classifier then train data set and show an accuracy with test data set. At last, it draws decision boundaries of iris data classes and scatter plot of data.
Original data

Standarized data (Z-score normalization)

Normalization (Rescaling)

As you can see, the calculated accuracies were the same however the shapes of decision boundaries were quite diverse. Let’s focus on the result of normalization (rescaling). The result has quite narrow boundaries and the rescaled data points were packed densely. Applying normalization usually tends to generate smaller standard deviations than using the standarization. It implies the data are more concentrated around the mean if we scale data using the normalization.
Actually this does not treat outliers well. The standarization is more robust for outliers. That’s because the original and the standarized results looked close, but the standarized one might be better than the original. Because the boundary curves looked more robust when we increased the neighbor points from 1, 3 and 6 (left to right). The right figure of the standarized data seems a dynamic and glanular capture.
- Standarization and normalization are gool tools in Scikit-learn library when you need to adjust data set scale (feature scaling) before applying machine learning techniques
- Standarization is the same of Z-score normalization (using normalization is confusing here) so it makes values of each feature in data to have zero-mean and unit-variance while normalization rescale the range of data to [0, 1] or [-1, 1]
- Applying feature scaling is good if either you’re going to use distance-based classifiers such as K nearest neighbours, SVM, or Neural Network or use classifiers that use gradient decent for faster convergence
- The standarization is more robust for outliers while the nomalization results more concentrated data around mean and standard deviation would be more smaller than the standarization
The choice of using normalization or standardization will completely depend on your problem and the machine learning algorithm you will use. You can always start by fitting your model to raw, normalized and standardized data and compare the performance for best results.
Feature Scaling for Machine Learning: Understanding the Difference Between Normalization vs. Standardization
KDnuggets has also nice writing about this topic.
Data Transformation: Standardization vs Normalization
One thought on “What are standarization and normalization? Test with iris data set in Scikit-learn”