Pandas is an open source data analysis and manipulation tool, that is widely used for machine learning purpose especially. To pack a library in Lambda layer is an efficient way to abstract the common library and the package that you use frequently like Pandas.
There are some public available layers already, so I’ll learn how to deploy a Lambda layer for Pandas library and introduce one of public AWS Lambda layer collection, Klayers.
Lambda layer was announced late 2018. There is only 1 AWS published layer that is including NumPy and SciPy, two popular scientific libraries for Python. So most of cases, we have to craft a layer and add it in AWS. I tested how to work by following the official guide.
New for AWS Lambda – Use Any Programming Language and Share Common Components
Lambda layers benefits are…
- Isolation and separation of the library and business logic
- Agility of deployment due to reduce depencencies of package
- Layered approach up to 5 layers and 250MB in quotas
Easier way, use the public available layer
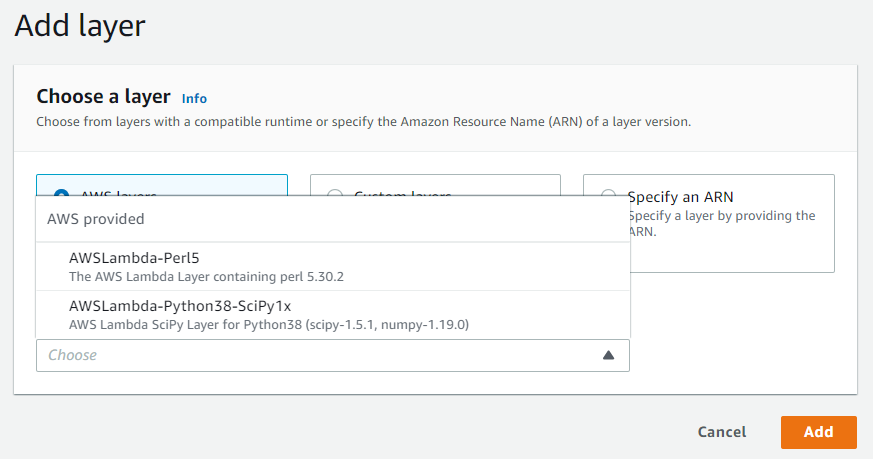
We’ve got only 2 AWS published layers that are AWSLambda-Perl5, and AWSLambda-Python38-SciPy 1x. These 2 are the only official layers.
So when we want other libraries or other versions of these libraries, we can look for public available arns at first. The most easiest way is to find the target arn in Klayers github.
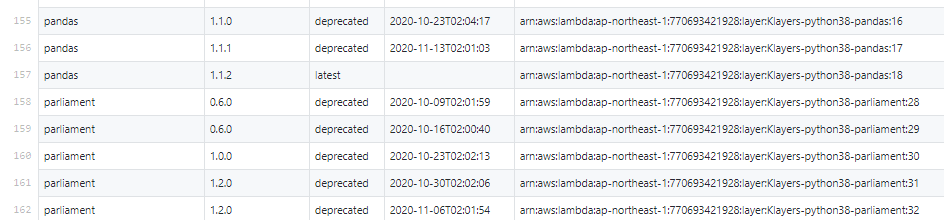
Klayers is building all latest packages for Python at 2am UTC every Sunday automatically and publish available arn information. Here is the csv list what libraries they are deploying and publish every Sunday.
More than 70 libraries are packed and deployed in AWS Lambda Layers. Please note that these layers are not supported by AWS officially so you’ll be responsible for your choice if you’d like to use.
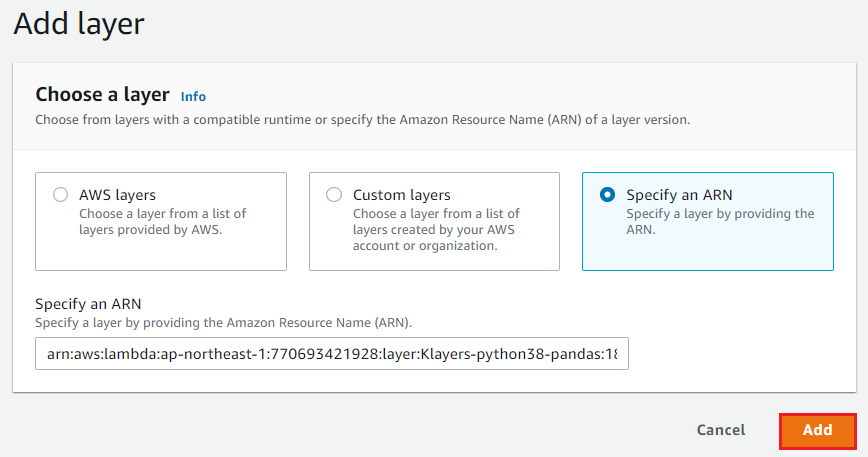
Once you decide a region and library version, check the arn from this link. This link is having all supported regions and libraries in Python3.8 runtime.
You can copy and paste the arn to specify an arn in Lambda layers accordingly. Off course, there are other version (Python3.7) too. All are automatically deployed and arns are published in github.
Deploy your own Lambda layer
Klayers supports only layers for Python3.7 and Python3.8 runtime as of now, therefore we’ll need to pack and deploy a layer by ourselves for other runtimes or other version of the libraries.
When you start thinking to create and deploy your own Lambda layer, you have to understand the underlying execution environment provides additional libraries and environment variables that you can access from your function code.
A simpler way to create your own layer is to deploy all required packages in the same environment Lambda function uses.
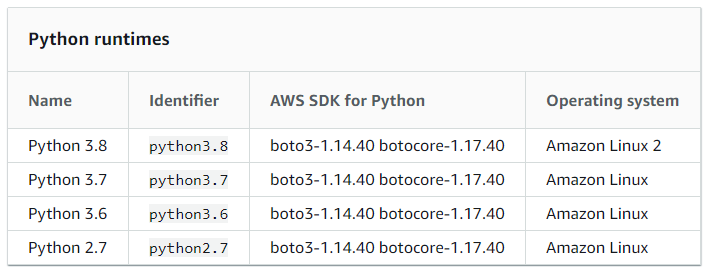
You can check an identifier of your runtime, for example the identifier is “python3.8” for Python 3.8. Then spin up an EC2 instance to craft your own layer package. The document explains what image and Linux kernal are used for each language and its runtime.

Creating your own layer by the same Lambda environment works fine however it causes tedious works for you. Need an EC2 instance, then set up language environment, resolve dependencies riddle, etc.
The more easier way would be to leverage lambci/docker-lambda to create a layer package locally inside the container that is sandboxed environment replicates the live AWS Lambda environment almost identically.
It includes installed software and libraries, file structure and permissions, environment variables, context objects and behaviors – even the user and running process are the same.
By using this Docker image, it just took only 5min to complete Pandas layer and publish it in AWS environment. Let’s take a look in the following section. I did this for Python3.8 runtime and tested it in Lambda.
- Write requirements.txt
- Write a package script
- (pull the Docker image)
- Install libraries and zip it by the script
- Publish the zipped libraries
First, let’s write out the required libraries in requirements.txt. In this sample I wrote only required libraries, we will run pip command with the flag --no-deps to install specified libraries without dependencies.
This flag tells tells pip to install only the libraries in requirements.txt without any dependencies. For example, without this flag, Pandas would need the underlying libraries in a layer such as Numpy.
As we’ve got Numpy/Scipy layer in hands already, I needed Pandas library without Numpy, pytz was also the one I needed. Here’s requirements.txt.
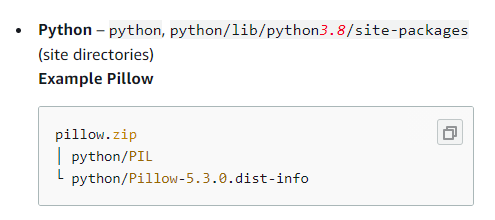
Write a script, this creates a directory locally and install the libraries mentioned in requirements.txt under the PKG_DIR directory that is python/ in this case.
Does this python/ directory mean anything?? Yes, this is important.
To include libraries in a layer, we need to place liraries in one of the folders supported by the runtime, or need to modify that path variable for your language. For python runtime, python is the location we can install the required libraries. Including library dependencies in a layer
Run the created script and zip files including the python directory. Here are the commands you may need to run.
$ chmod +x package-layer.sh
$ ./package-layer.sh
Collecting pandas==1.1.2
Downloading pandas-1.1.2-cp38-cp38-manylinux1_x86_64.whl (10.4 MB)
Collecting pytz
Using cached pytz-2020.1-py2.py3-none-any.whl (510 kB)
Installing collected packages: pandas, pytz
Successfully installed pandas-1.1.2 pytz-2020.1
$ zip -r my-Python38-Pandas112.zip .At last, I used aws cli to publish the provisioned layer to AWS. If you pack the required files in a zip file again, the published layer version will be ascending from 0.
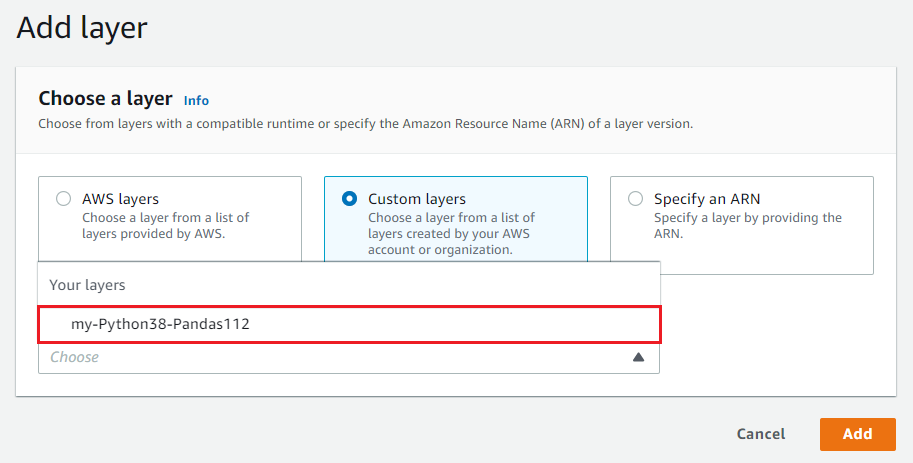
$ aws lambda publish-layer-version --layer-name my-Python38-Pandas112 --zip-file fileb://my-Python38-Pandas112.zip --compatible-runtimes python3.8Your layer must appear under Custom layers menu in Lambda by clicking Add layer as below.
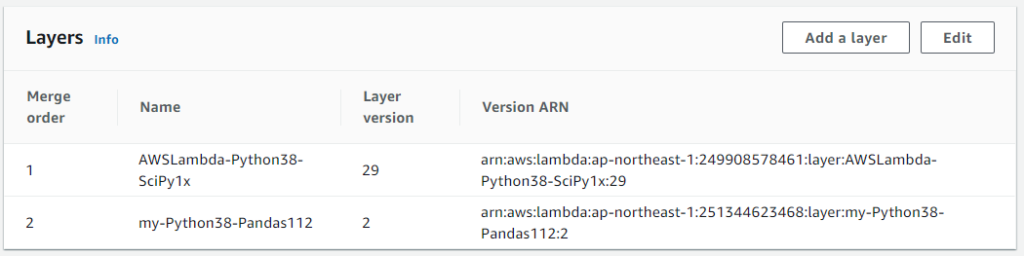
Both the official Numpy/Scipy layer and Pandas layer worked in harmony. I was able to run my lambda function to read csv file and convert it into Pandas DataFrame in AWS.
To wrap up, there are some limitations and quotas when you use Lambda function, and Lambda Layer has some advantages for some reasons including a single lambda function size limitation.
To use Lambda layer, the most easiest way is just to find public available arn, but it might not guranteed that those arns are always maintained and usable because those are not officially supported.
If you create your own layer, there are 2 ways either spinning up the same environment in an EC2 and craft a layer package or use lambci/docker-lambda container image to create own layer and publish it to AWS Lambda layers.