In AWS infrastructure, individual AZs (availability zones) are isolated secure data centers and they are physically located in different distant places. So If you span your resources across AZs availability of your services will be secured in a region.
However if a wide area disaster happens not in a region level but rampage whole places in the country, in this case, we would need to consider region-across availability and fail-over mechanism between the regions.
AWS Aurora Global database is an option for such scenarios, that can add up to 5 secondary regions and you can create DB cluster in each secondary region. We can enable Aurora DB cluster endpoints in the secondary regions also.
This is the guide how to set-up the primary and the secondary region’s DB cluster with Cloudformation template in a nutshell. As long as I checked, there hasn’t been much concrete information how to create a global cluster of Aurora with CloudFormation.
What are characteristics of Aurora Global database?
Before delving into details and CloudFormation template, I briefed the characteristics and the considerations about Aurora Global database. With the characteristics, you will understand Aurora global database is not only for disaster recovery (availability purpose) but also useful for scalability purpose.
Using Amazon Aurora global databases
- Up to 5 secondary regions can be added upon primary region
- Primary DB cluster’s data can be replicated across the secondary regions within a second (up to 5 seconds, RPO)
- Need a manual promotion of one of the secondary regions to take write/read endpoints under a minute (RTO)
- Secondary region’s clusters are low-latency read endpoints, so the secondary region’s cluster can have up to 16 read replica
There are some limitations of Aurora Global database. You can check the bottom of this page.
Create a global database cluster and primary DB cluster
As we need to have a secondary region’s DB cluster in a different region from a primary region, we need to separete CloudFormation stacks. Because CloudFormation stack is tied with region. You can modify the primary region template and set specific region to run the template for secondary resources.
In this hands-on it was easier way to create one template to create a global database cluster and primary DB cluster in it, and the another template to create a secondary DB cluster and add it to the generated global cluster group. If you’re familier with console or aws cli, you can check this documentation how to do it.
There are some configuration points for your primary DB cluster.
- AWS::RDS::GlobalCluster is mandatory to contain a single primary cluster and secondary clusters if it’s not empty
- SourceDBClusterIdentifier takes the primary DB cluster identifier and configure the cluster primary
- EngineMode property can be configured “provisioned”, “global” isn’t required for Aurora PostgreSQL (read here)
- GlobalClusterIdentifier: <identifier> is not required in the DBCluster resource in this sample, because we create a DB cluster first
$ aws cloudformation create-stack --stack-name aurora-globaldatabase --template-body file://01_aurora_global_database.yaml --parameters ParameterKey=MasterPassword,ParameterValue=password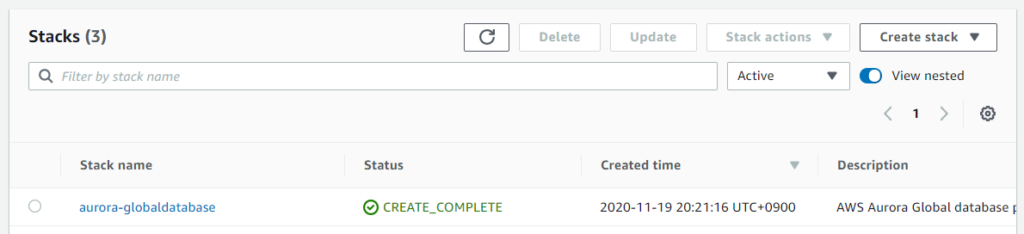
Create secondary DB cluster and add it into the group
We have created the global cluster group and the first primary DB cluster. With SourceDBClusterIdentifier in GlobalCluster resource, we defined the primary DB cluster’s identifier, so the primary cluster went in the global cluster group automatically. Without this paramter, an empty global cluster group would have been created.
Next, we will create a second DB cluster in the secondary region where this region must be different from the primary region. In this template, we don’t need to create a global cluster resource. We need to configure the global database identifier and SourceRegion property to let a cluster know where the primary region’s cluster exists.
There are some configuration points for adding the secondary regions.
- No need to create a global cluster resource, but need the global cluster identifier under the secondary cluster’s configuration
- Secondary cluster must recognize source region when it’s created at the same time with SourceRegion property
- Primary cluster and secondary cluster versions, do not need to match (maybe minor version level) therefore upgrading the secondary cluster first is recommended
You need to switch deploying region from the primary region to the secondary region when you run CloudFormation template. I preferred to use aws cli in here. MasterUsername and MasterPassword must not be set for the secondary DB cluster.
$ aws cloudformation create-stack --stack-name aurora-globaldatabase --template-body file://02_aurora_global_database.yaml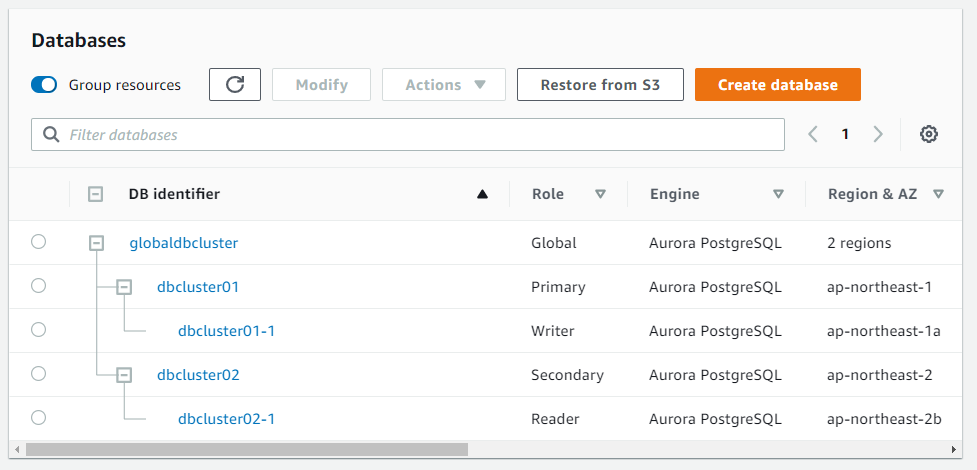
Some properties should be different from the primary region’s one in the secondary DB cluster configuration. GlobalClusterIdentifier is clearly needed in the secondary region’s cluster. Please take care of these configurations when you run CloudFormation template for the secondary region.
- GlobalClusterIdentifier: <identifier> is a must in the secondary cluster
- SourceRegion: <primary region> is needed in the secondary cluster
- MasterUsername and MasterPassword are not required
- DatabaseName can’t be configured for cross region replication cluster

To wrap up, AWS Aurora global databases support both high availability and scalability in cross region fashion. Storage data can be replicated to the secondary regions within a second (RPO). When your database gets degraded or isolated in your region, you can promote one of the secondary DB clusters to take full read/write workloads within a minute (RTO).